This very minor NarraFirma release does nothing but fix some warnings I got from WordPress when I released version 1.6.8.
As always, if you find any bugs – or find anything in NF confusing or hard to use – please tell me on the GitHub issues page.
This very minor NarraFirma release does nothing but fix some warnings I got from WordPress when I released version 1.6.8.
As always, if you find any bugs – or find anything in NF confusing or hard to use – please tell me on the GitHub issues page.
This very minor NarraFirma release adds a notes field to each question category (about each group’s status, ability, expectations, and feelings) on the “Describe participant groups” page.
As always, if you find any bugs – or find anything in NF confusing or hard to use – please tell me on the GitHub issues page.
This very minor NarraFirma release adds a bit more functionality to the story-form building and translation facility. Specifically, you can now set (and translate) the “Does not apply” slider label in general, not only for specific questions.
As always, if you find any bugs – or find anything in NF confusing or hard to use – please tell me on the GitHub issues page.
This smallish NarraFirma release adds some quality-of-life improvements and fixes some small bugs.
In the Catalysis part of NarraFirma, display lumping (on-the-fly data manipulation) is proving to be quite useful. However, I recently realized that it can be used for more than just lumping together similar answers. So I extended it slightly.
I did think about the fact that people could use these new functions to distort what people say. But there are so many ways to distort what people say that I don’t think withholding this functionality would deter anyone doing that if they wanted to. After all, you could just export the data to a spreadsheet, change it there, and import it again. Also, this functionality could be quite helpful in situations where the collected data is too messy to be useful without some cleanup. The general rule is: in participatory work, if you use any form of data manipulation, in any project, using any software, you should always be transparent about what you did and why.
My original idea for story cards was that choice questions would provide context by displaying all possible answers for each story, with the chosen answers marked in bold. However, for some choice questions (those with many and/or long answers) a show-it-all display confronts participants with too much text to wade through.
So I have implemented an option where you can show or hide non-selected answers in your story cards.
I also made the between-answer display character(s) customizable, so your answers lists can say “happy/hopeful” or “happy, hopeful” or “happy and hopeful,” or anything else you like.
When you are annotating stories, you might not think of annotation questions in the same order as you would like to answer them. So I added an option to the “Write annotation questions” page to specify the order of annotation questions on the “Annotate stories” page. While I was doing that, I added the option to create headers above groups of questions (to make the annotation process easier).
As I use NarraFirma on projects, I keep wanting new reports (“if only I could see this”), so I “scratch the itch” and build them, then use them in my local copy of NF. Later, if I think other people might want to see the same reports, I clean them up and add them to NF. (I’ve been doing that for a long time.)
I recently worked on a project using NF, and I wanted (so I created) a summary correlations report. I think you might want to see that report too, so I kept it. NF can now spit out (to CSV) a table that summarizes the significant positive and negative correlations in all subsets of stories with all answers to all choice questions. This is a good report to glance over when you want a quick idea of where your correlations lie – before you go through your (possibly thousands of) subset correlation graphs.
If you are doing a project with NF and there is a report you would love to see, tell me about it on the GitHub issues page. Depending on what sort of report it is and how it fits into NF’s existing architecture, I might be able to build it for you (maybe quickly) and add it to NF. Of course, whether I will have the time to do that will depend on many other things (which are mostly out of my control). But please do reach out if this happens to you, because I would like to hear what would make NF work better for you.
I decided to rename the “Spot-check graphs” page to “Review graphs.” I did this because recently (well, recently in the glacial way my mind works) it came to my attention that some NF users have been using that page not to spot-check graphs for completeness during story collection (as I thought they would) but to look for patterns in their data without going through the catalysis process.
I had not thought of that use for that page. But I can see that the full catalysis process might not seem worth doing on very small projects. In the last NF update (which happened after I heard about this) I improved the spot-check/review page. This time I thought I’d rename the page to address the confusion people must have over what it can be used for.
By the way, I did think a little about building a sort of dashboard page that (like the survey) could be accessed by project participants who do not have access to the entire project. That’s a harder task than it may seem. Just in case anyone wants to know why, I’ll explain.
Every PNI project needs to have a control point somewhere in the collection process. This is because people often volunteer information you asked them not to provide, such as their phone numbers or the phone numbers of other people. (You would be amazed how often people do this.) As a result, all PNI projects must go through a phase in which personally identifying information is “scrubbed” out of the stories and other data. This has to be done before the stories (and other data) can be shown to any participant groups. This is why the code that runs the NF survey is completely separate from the code that runs the NF project management interface. They are basically two different pieces of software.
So a NF dashboard that is visible to project participants would have to have some way to show people only the stories and data that had been reviewed and marked as safe to share. The data architecture of NF doesn’t currently have any way to mark stories (or story collections) as safe to share. We would have to add a way to enter and store those markings. That’s not hard to do, but we would also have to find a way to deal with legacy data that has no such markings. Dealing with legacy data has been a big part of my work on NF for almost a decade. I’m proud of the fact that the very first NF projects can still be read and used without any translation issues. I want to keep that record clean. I think probably the best way to do that would be to assume that data without markings cannot be shared, but I would like people to be able to mark legacy data as shareable using some process.
Also, building a participant dashboard would require us to write a whole new set of separate access and display scripts, both client and server, that are similar to the survey scripts but that require a new intermediate level of permission (and a permission-granting interface that also deals with missing permissions in legacy projects). We could do all of this if we had the time and funding to do it, but right now we don’t. It’s a good someday idea, though. Who knows, maybe someday we will get a nice big grant so we can make NF work even better for everyone. :-)
I also made lots of little tweaks to the software as I used it and talked to users about it. For example:
As always, if you find any bugs – or find anything in NF confusing or hard to use – please tell me on the GitHub issues page.
This minor NarraFirma release fixes one small bug that applies only to older projects.
A helpful user told us about a strange problem. On the “Explore patterns” page of NF, when they double-clicked on a pattern, NF was setting the “remarkable” flag of that pattern to “yes” – on its own – and they could not set it back again.
What caused the problem was a bit of code we wrote to update legacy data back in 2019. It was supposed to add a “remarkable” flag to any pattern that had at least one observation but no “remarkable” flag. That’s because, prior to version 1.4.0 of NF, there was no remarkable flag.
The problem was that this update was creating a circular interaction because it was (accidentally) being done while the page was being redrawn. Changing the data caused the page to redraw, which changed the data, causing the page to redraw, and so on. Double-clicking was not the only way to get the cycle going; it could also happen by clicking the arrows under the table. But double-clicking made the cycle more visible, which is probably why we never noticed it before. (Double-clicking has no actual meaning in NarraFirma, so we’ve never done it.)
To fix the problem, we changed the code so the updating only happens when the user changes the “remarkable” flag by hand. This does mean that people who have legacy data (created before NF 1.4.0) will have to manually update their remarkable flags. But that is probably few people at this point, and now it won’t happen “on its own.”
Thank you, user! And as always, if you find any bugs – or find anything in NF confusing or hard to use – please tell me on the GitHub issues page.
This minor NarraFirma release adds one nice-to-have thing, but mostly fixes little bugs.
When I’m helping people work on catalysis, I often advise them to save time by ignoring graphs that don’t go “through the story.”
What does that mean? Well, say I asked people to share stories about a topic, and I also asked how old they are and where they live. This means that, among all the graphs generated by NarraFirma, there will be a graph of age versus location. That graph has nothing to do with the stories people told. Once in a while a graph like that will be useful, but not often. Not-through-the-stories graphs are worth a quick look, but I wouldn’t put a lot of time into considering them, since they are not why you did the project.
So I have added an option, on the “Configure catalysis report” page, to hide graphs that involve no questions about stories. You might find this option useless. However, if you happen to have a lot of questions about people, especially if you threw in a lot of demographic data you happened to have handy, hiding not-through-the-story graphs could save you some time.
When you reset a project, NF makes a backup copy in case you change your mind later. (We really don’t want you to lose your data.)
In the WordPress version of NF, I had recently (like a few years ago) found out that our scheme of adding the date to the backup table name was breaking the MySQL database, because MySQL table names have a character limit. So I changed NF so the backups just put a “b” in place of the “j” (for journal) that was usually in the name.
When I did this, I had assumed that the “rename” MySQL command would overwrite any existing table with the same name. It doesn’t. It throws up an error. So if you happened to reset the same project twice, NF would refuse to do it.
I have now changed this so that any NF reset backup table – for any project in your NF installation – is called
[your WordPress prefix]narrafirma_reset_backup_[date/time]
So in the unlikely event that you need to recreate a NF project from a reset backup, you will need to find the table by its date, not by the project name. Since (as far as I know) this has never actually happened, I think it is acceptable to remove the project name from the table name to make space for the date and time.
Note that the date/time in the table name is in UTC, not your local time zone.
People never use software the way its developers think people will use it.
Funny story: One of the first pieces of software I wrote for money was a database system for a former professor. He told me what he wanted, and I built it. Then we met so he could look at what I had built. He sat down at the computer, put his hands on the keyboard, and somehow accidentally typed – in perfect sequence – the three keys that would immediately exit the entire database system. He said, “I broke it!” and I think my mouth dropped open. Anyway, after that, I added a special prompt to make sure the system would ask the user if they really did want to exit the system, just in case that ever happened again (though it probably never did).
NarraFirma has more users than ever, and they keep doing things I never do. Recently a user typed in a question short name with a forward slash in it, something like “Preference/choice.” It seems obvious – now – that people might do that, but I never thought of it before. The problem is that it creates a conflict.
The NF module that looks things up, the “valuePathResolver,” uses a forward slash to separate data identifiers in a lookup sequence. For example, when you are on the “Configure catalysis report” page, and you click on a type of graph to show, the code for that page saves your choice with the “valuePath”
/clientState/catalysisReportIdentifier/graphTypesToCreate
Meaning: ask the “clientState” module (which remembers what’s going on in your browser client) what the currently selected catalysis report is. Then save your choice in that report under the field name “graphTypesToCreate.” That’s why you can see the same types of graphs when you come back to the “Explore patterns” page again, even if you closed your browser in between.
The surveying code does not use the valuePathResolver, so a question with a slash-containing short name does not cause any data to be lost. But the table widgets throughout NF can’t find the data. They all use the valuePathResolver, and it chokes on the slash. (It thinks the question name must be the first part of the name, before the slash.)
I decided not to change how the valuePathResolver works, at least not yet. I didn’t write it, and it’s used all over the system, and I don’t want to create any new bugs. Instead, I wrote an extra validation step. You can no longer include a forward slash in any short name identifier. It’s not a beautiful solution, but it should fix the problem. If we ever get enough time to transition the badly-designed short-name-identifier system into a more robust all-UUID-identifier system, this conflict will go away.
As I told the user who discovered and then helped me track down this problem – and I want to say a huge thank you to that user – the “price” of free software is that its users and its testers are the same people. I would love to hire a dedicated tester to find other conflicts like this, but I don’t think anybody would work on it for the same salary I’m getting (nothing). So there will continue to be surprises like this – hopefully fewer and fewer as we go.
While I was messing with the Reset functionality, I decided I hated the Project admin / Import & export page, so I cleared it up a little.
I also fixed a few more bugs that were reported by users (or that I happened to notice while fixing other things).
As always, if you find any bugs – or find anything in NF confusing or hard to use – please tell me on the GitHub issues page.
This minor NarraFirma release adds bulk export of graphs and statistics. It also fixes a few bugs.
On the “Explore patterns” page, you can now export all of the graphs and/or statistics for all of the patterns in the list, even if you have not written any observations for them. This is for situations in which you want to use NF to generate graphs and statistics, but you don’t want to use it to build catalytic material. Or you want to show someone the graphs you have found before you start writing your observations.
I also fixed a few small bugs, as usual, including a bug that might have been slowing down the “Explore patterns” page for you.
As always, if you find any bugs – or find anything in NF confusing or hard to use – please tell me on the GitHub issues page.
This minor NarraFirma release makes a few small quality-of-life improvements and fixes a few bugs.
On the “Print catalysis report” page, you can now save a CSV (spreadsheet) file with just the observations and interpretations you wrote, for pasting into whatever software you want to use to prepare your catalytic material. Paired with the option to spit out just the graphs associated with your observations, this should make creating your catalysis materials even easier.
Note that this new bits-and-pieces option ignores any clustering you do inside of NF. You might or might not care about that.
If you would like to write your catalysis reports in NF (perhaps to use its clustering interface), I recommend that you give pandoc a try. It works like a charm to convert NF’s HTML reports into any format you like.
When you’re looking at graphs in NF, it is not immediately obvious that you should click and drag on them to select stories. So I added a little bit of text below the graphs on the “Spot-check graphs” and “Explore patterns” pages to let you know that you can do that.
Another thing that happens sometimes when you are working with patterns on the “Explore patterns” page is that you forget the longer version of a question on the graph. So now, in the “Things you can do” list under each graph, there is an option called “Show survey questions for this pattern.” If you choose that option, then click “Do it,” NF will pop up a dialog that gives you the full text of the question, along with its (non-lumped) answers.
I also fixed a few little bugs.
As always, if you find any bugs – or find anything in NF confusing or hard to use – please tell me on the GitHub issues page.
This minor but essential NarraFirma release fixes three categories of bugs.
In the last update (v1.6.0) I introduced a show-stopper of a bug that meant you couldn’t create the first story collection in a project. Sorry, that was sloppy of me. I tested the new dialog in a project that already had story collections in it, and I forgot to think of the new-project situation. It is fixed now.
We recently had the opportunity to have a whole bunch of people use NF at the same time. A whole bunch of updating bugs popped up. It was frustrating! But so very useful. I would like to apologize to the users who encountered these bugs, and to thank them for their patience and understanding.
The worst of the bugs came about due to a misunderstanding of how mithril handles screen updates during user editing.
There is a critical assumption in the version of mithril we are currently using in NF (0.2.0). When a mithril element gets a redraw message, it redraws itself using its value function, which draws data from the datastore. The current value of the text box (that is, whatever you were typing) is overwritten by the datastore value.
If you are using the oninput method to save changes to the datastore, this is not a problem, because the oninput method fires on every keystroke. So every character you type is immediately saved to the datastore, and differences don’t pile up.
However, we didn’t want to use the oninput method in NarraFirma text boxes. Saving to the server database on every keystroke would multiply the number of messages so much that the NF server would slow to a crawl. Plus, NF databases would be orders of magnitude bigger. So we decided to use the onchange method, which only fires when you leave the field or hit Enter. This is why, when you are typing into a text box in NF, you have to hit Enter or Tab, or click outside the box, to save what you have typed to the server.
We have always been using the value function to set an element’s displayed text. But in a multi-user situation, the value function might be called by an update message while the user is in the middle of editing a text box. In our session last week, people were having texts disappear in front of their eyes.
This was a complete shock to us, because we should have seen it before. We have tested the multi-user aspect of NF many times over the years. But I think we never typed a lot of text into a field, over a long period of time. So we never saw these interruptions happening. When you are typing “test123” into text fields over and over, you never get a chance to see what happens when you spend a whole minute puzzling over what you are going to write there.
Actually, one user did tell me that they were seeing multi-user collision bugs four years ago. I assumed that they were talking about two people working on the same field at the same time. So I set up a conflict-handling system to handle that situation. It worked! But only for that one situation. There must have been other conflicts that I continued to not see, probably because I continued to test by typing in things like “test123.” That user never told me about any more multi-user conflicts, so I thought the problem was fixed. But looking back, maybe what actually happened was that they finished their project and stopped setting up the long-edit conditions under which the other bug was showing itself.
This onchange-overwrite problem was discussed on the mithril Github issues list way back in 2016. The mithril user in that discussion, like us, was using the onchange method in a situation in which updates were coming in from elsewhere. Their workaround was to use the config function to “keep a separate ‘work-in-progress’ state property and another ‘real’ property on the side.” That was a great idea. We implemented it (just now, mind you, not eight years ago) and it works.
Some readers of this blog will be surprised to hear that we are still using mithril 0.2.0, which came out several years ago. The thing is, we need to set aside a nice big chunk of time to make all of the careful changes required to upgrade our mithril version to the current version (2.2.2). It sounds like mithril is much nicer now, and we are eager to do this, but we just never have that much time free. Hopefully we will find a way to get to it someday. In the meantime, mithril 0.2.0 still works fine, except for this one problem, which is now fixed. (The config function goes away in later mithril versions, so we will have to change how we do text-box updates during that refactoring.)
We did see some other updating bugs in our multi-user session. They were all failures to update various screen widgets when new data came in (like when you were annotating stories and another user added a new answer for an annotation question). Those are fixed now too.
Another new bug came up recently. A user had entered answers for a fixed-list question, and (probably without noticing) had included extra white-space characters (spaces and tab characters) in the answers. (This was probably from pasting the answers in from somewhere else.)
NF doesn’t care if you have a lot of extra crap in your answers – or at least I thought it didn’t. In reality, there was a hidden assumption in the filtering and display lumping features of NF. To use those facilities, you enter a bunch of answer names, and NF parses the text you enter, trimming white-space characters as it goes.
Do you see the problem? The answers you specify in the filter or lumping command cannot match answers that have extra spaces in them.
So, after some thought, I fixed the problem on both sides. NF now trims out whitespace characters when it compares data during the filtering and display-lumping processes (that’s for legacy data). And it will no longer allow you to enter fixed-list answers with leading or trailing white-space characters.
The new restriction on white-space characters could affect your legacy data.
I think this sequence of events is unlikely to happen to anybody, because probably few people have leading or trailing white-space characters in their answer lists. But if this does happen to you, you can fix the mismatch.
If you run into this problem and have trouble solving it, feel free to ask me for help (cfkurtz at cfkurtz dot com). I may need to ask you to send me your project so I can fix the data for you. (I always delete projects again as soon as I have fixed them.)
I would like to say a big thank you to the users who told me about (and had to deal with) these bugs. As always, if you find any bugs, please tell me on the GitHub issues page.
This major NarraFirma release improves the interface and the surveying system.
In version 1.5.18 of NarraFirma, I added something annoying to the interface. When you had entry fields open in an editing panel (under a list), and you clicked on one of the navigation buttons or links at the top of the page, NF would ask you to click the Close button so it could validate your open fields. I did this because several NF users had run into problems due to missing but necessary data (like an empty “short name” identifier for a question).
I didn’t like adding that popup, and I didn’t like clicking it either. But I didn’t know how else I could help people avoid having problems with missing data.
Ever since then, I’ve been trying to think of another way to handle validation on page changes. In this version I finally figured it out. Now, when you click one of the navigation buttons or links at the top of the page, NF pretends that you clicked the Close button (and runs the data-validation checks it would run if you clicked it). That’s better.
[By the way, one of our biggest mistakes in designing NarraFirma is that many of the objects in the system (questions, forms, answers) are connected by their (user-entered) names, which cannot be changed without making a mess. For example, answers to choice questions are stored in each story as answers to questions. That was a huge mistake. Each stored answer should have been a UUID, not the text of the answer. If we had done that, users would have been able to change the texts of answers without breaking connections. In retrospect, every single reference should have been a UUID. (Some are! But most aren’t.) We would like to fix this. But we will have to step very carefully to avoid breaking any existing data. It is on the wish list, and I think it will happen eventually, if we are able to keep working on the software.]NarraFirma keeps its stories in story collections: containers for stories. Each story collection is associated with a story form (or questionnaire or survey) that determines how the stories in the collection are to be gathered or entered into the system.
When you create a story collection, NF copies a “snapshot” version of the selected story form into the story collection. It needs to do this because, for security purposes, the surveying part of NarraFirma is an entirely separate program. It knows nothing (well, nothing else) about your project.
In our very first version of NF, there was no way to change the snapshot form once it was copied. It was unalterable. But we soon realized that it is sometimes necessary to make small changes to a story form after some stories are collected – to fix typographical errors, for example, or to add explanations of commonly misunderstood questions. So we added an “Update Story Form” button – and a warning to use it only to make changes to the form’s appearance, not to the structure of its data.
Over the years I have seen a gamut of responses to that button and its warning. Some people have been afraid to use it to fix even the tiniest of typographical mistakes. Others have happily clicked the Update button after making major changes to the types of data the story form collects.
To fix both of these problems, I have now added a data-conflict checking system. When you click the Update Story Form button, NF now looks to see if you have any data that will be invalidated by the differences between the snapshot and current versions of the form. It tells you what it found, and it stops you from updating the form if you will lose data by doing it – unless you override its decision and tell it to update the form anyway. (The stories that will lose data could be test stories, after all.)
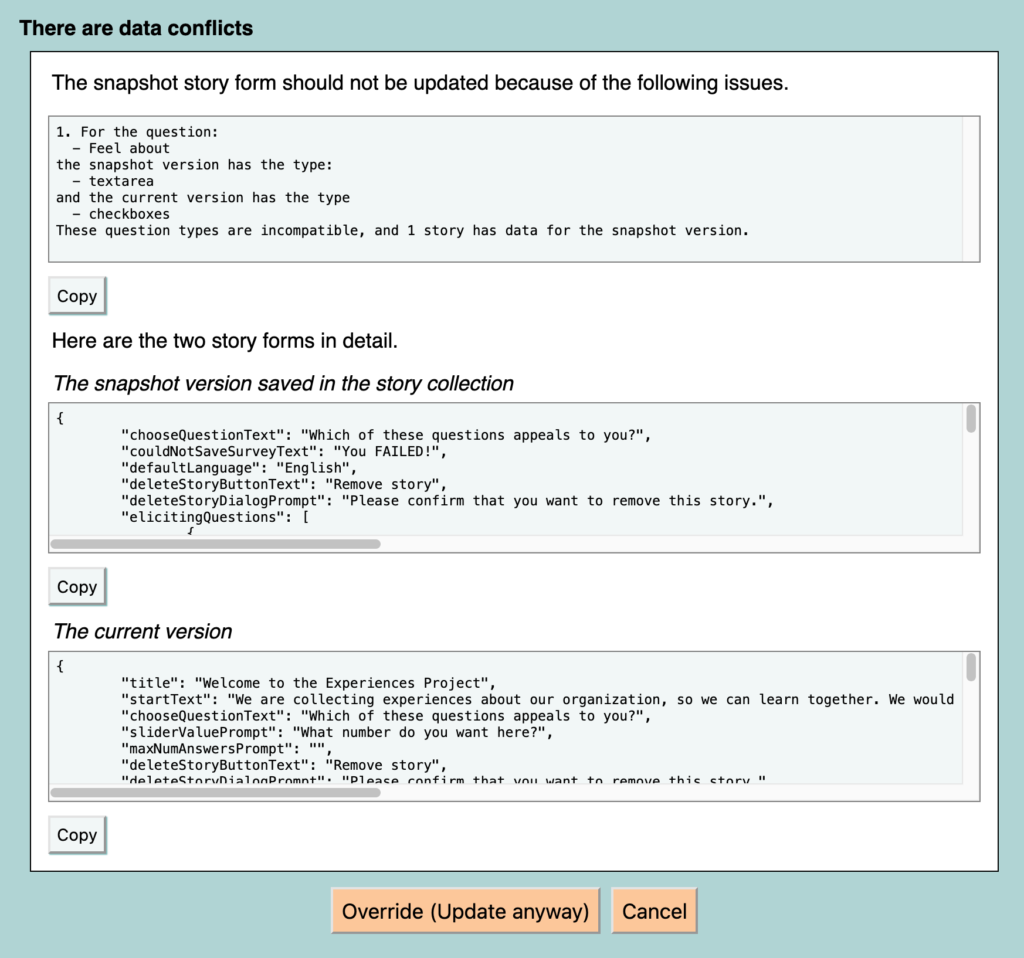
You can also check for data conflicts before you click the dreaded Update button, just in case anyone is still worried about using it. I have also improved the help-page explanation of what you can and cannot change in a story form after you have begun collecting stories.
When we first thought about improving the link between story forms and story collections, we thought it might be best to “lock” any story form that was actively linked to a story collection (so you couldn’t mess with it). If we did that, we thought, users would need a way to copy a locked story form and change the copy. So we needed a cloning system.
The table widget in NarraFirma once had a “Duplicate” button, but it was a prototype button that we never finished implementing. So we recreated the button and made it work. Since it’s on a standard widget, it works for everything, not just for story forms.
But then, after doing that, we realized that locking the story form without locking its questions would not protect story data very well. You could still invalidate your data by changing a question to an incompatible type. And if it would be messy to have locked story forms, it would really messy to have locked questions as well. So we backed out of the whole locking idea and instead developed the reporting idea I described above.
But the duplication button is nice, so we kept it. Everything in NarraFirma can now be cloned.

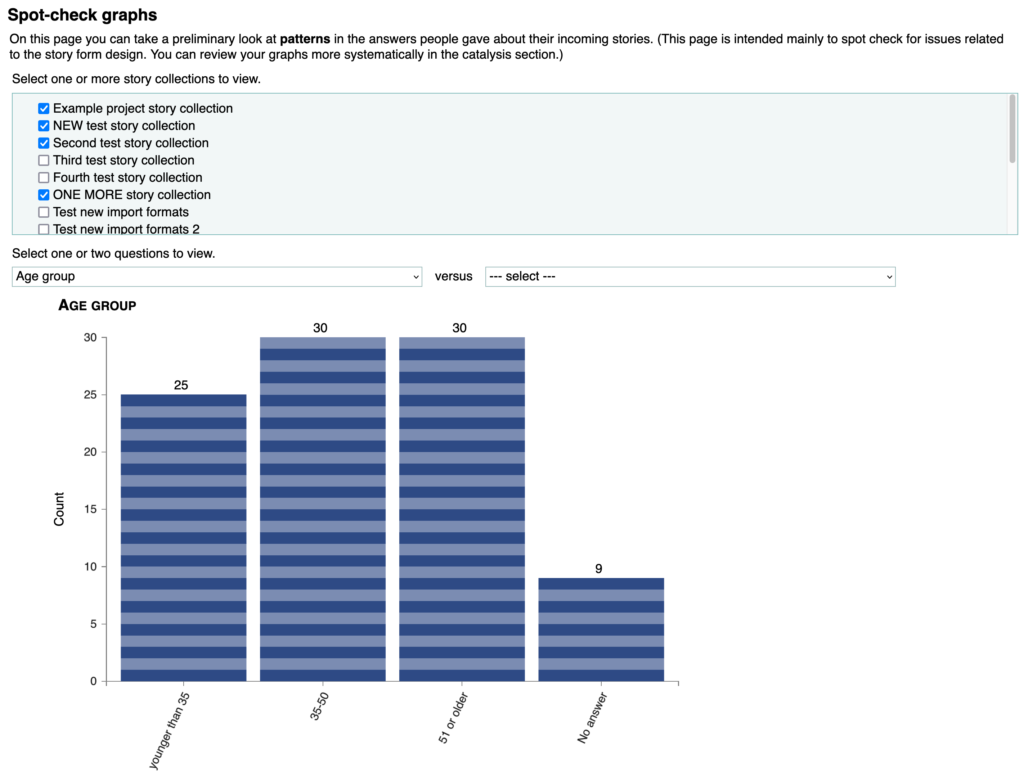
Here’s another bit of residue left over from the let’s-lock-story-forms idea. We were thinking that asking users to create lots of locked story collections would make the “Spot-check graphs” page less useful, because they would have to check each collection separately. So I wrote myself a sticky note to change that page so it could merge data from multiple collections.
After we abandoned the locked-story-form idea, I looked at the sticky note and thought, eh, that was still a good idea. So I did it anyway. Now, instead of a drop-down list of collections to choose from, you get a bunch of checkboxes, and NF shows the stories in the selected collections all mixed together, as if they were in one giant collection. That’s how catalysis works, so now this page works that way too.
I am ashamed to say that I have been meaning to add multi-column story cards for ages but never got around to it. It didn’t take that long. I should have done it years ago. Sorry about that.
Now, when you print your story cards, you can specify how many columns to put them in. Since the scale values are in embedded tables, this can look messy if you choose more than two columns; so I added another option to set how many characters are used to draw each scale (from 20 to 100).

I’ve tested a copy-and-paste workflow from the generated HTML to Microsoft Word and LibreOffice, creating story cards you can cut apart (with a paper cutter) to make more card-like objects for people to work/play with during sensemaking. (I added a description of these workflows to the help page for the “Print story cards” page.) You can also use the excellent pandoc utility to convert your story-card file to the format you want to use.
Finally, I fixed a few little bugs.
I would like to say a big thank you to the users who told me about bugs and about things they found confusing or hard to use. As always, if you find any bugs – or if you find anything in NF confusing or hard to use – please tell me on the GitHub issues page.